Rules
Prerequisites
- Security Roles: System Administrator or Duplicate Manager Admin
- At least one added entity (refer to Manage Entities).
Adding a Rule
- Open the Duplicate Manager App and navigate to Entity Configuration.
- In the top panel, click the currently selected entity’s name to open the Entity Select Dropdown, and choose the entity you want to configure.
- In the header bar, click + Add Rule.
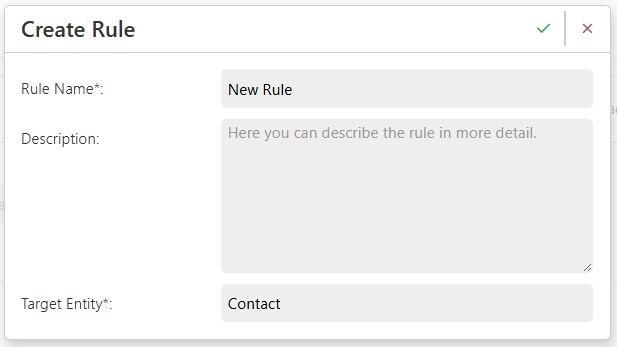
- In the popup:
- Enter a Rule Name.
- Select the Target Entity you want to compare this entity’s records with.
→ For more information on using a different Target Entity than the Source Entity, see Cross-Entity-Rules. - (Optional) Add a Description to explain the rule’s logic or leave notes for other users.
- Click Confirm (✔) to create the rule.
Don’t Forget to Activate Your Rule!
Configuring a Rule
When you create a new rule, the first column configuration is automatically added. You can then include as many additional columns as needed — combining them to fine-tune how records are compared.
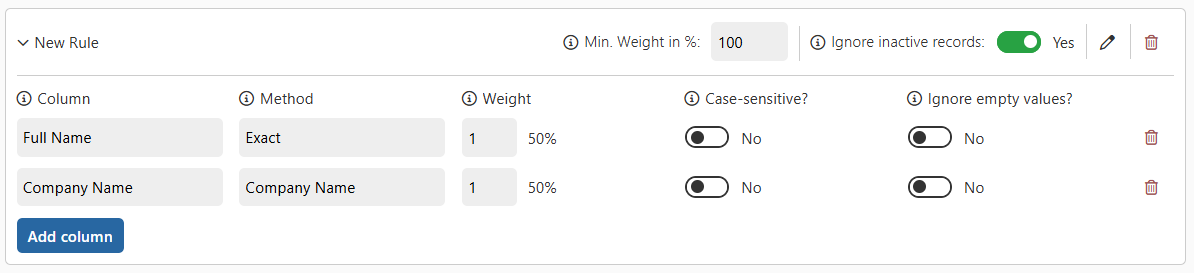
Column Configuration Options
For each column in a rule, the following options are available:
- Column
The field from the source entity that should be compared between records. - Matching Method
Determines how values in the selected column are compared. For example, Exact, Company Name, or Fuzzy.
→ Learn more: Matching Methods - Weight
Assigns a numerical weight to the column, indicating its importance in the overall comparison.
You can adjust these weights to make some fields more significant than others when determining duplicates. - Case-Sensitive?
Determines if comparisons consider letter casing. For example, with case sensitivity enabled, “Contoso” and “contoso” are treated as different. - Ignore Empty Values?
Specifies how empty fields are handled:
Yes: Empty fields are ignored during comparison.
No: Empty fields still contribute to the total match score.
→ See examples: Empty Values
Minimum Weight
Each rule has a Minimum Weight, which defines the combined score that must be reached for two records to be considered potential duplicates.
For example:
- If you want all columns to match before two records are classified as potential duplicates, set each column’s weight to 1 and the rule’s minimum weight to 100%.
- If partial matches are acceptable, you can lower the Minimum Weight accordingly.
→ For an explicit example, refer to Rule and Column Weight.
Ignore inactive Records
In the rule header, you can also choose to ignore inactive records.
- If set to Yes, only active records are considered in duplicate detection.
- Example: When opening an inactive record, the system will skip this rule, and jobs won’t compare inactive records under this rule.
Cross-Entity-Rules
With Duplicate Manager, you can also create rules where the target entity is different from the source entity. This enables duplicate detection across different entities.
To create a Cross-Entity Rule, simply select the target entity you want to compare records with when creating a new rule. The rule interface will now look slightly different compared to a standard (same-entity) rule:
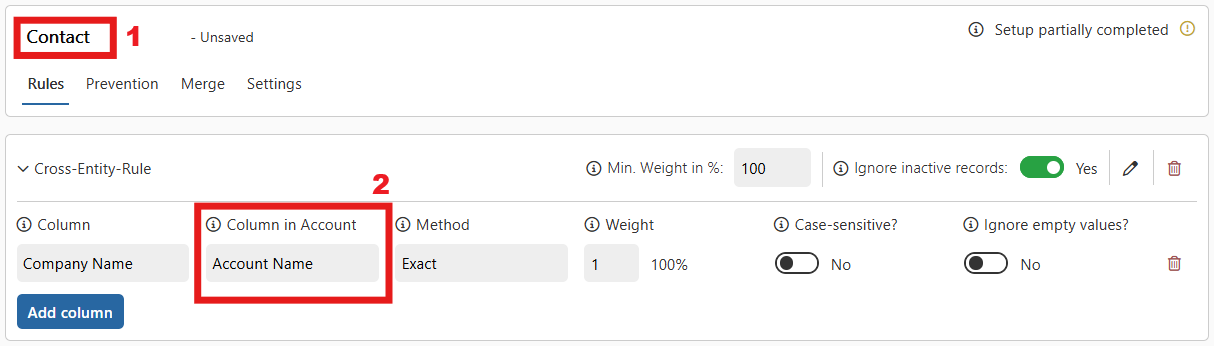
In this example, the rule is set up from the source entity Contact (1) with the target entity Account (2). In Cross-Entity-Rules, an additional setting called Column in <EntityName> appears (2). This setting defines which column from the target entity (Account) will be compared with the selected column from the source entity (Contact). For instance, here the field Company Name from the Contact entity is compared to the field Account Name from the Account entity.
Rule Examples
In this section, you’ll find examples of different column settings. Click on an item to expand and learn more.
Empty Values
Enabling Ignore Empty Values helps you detect duplicate records even when some fields are missing or incomplete.
However, be cautious — this can increase false positives, flagging records that may not truly be duplicates.
Let’s consider the following two contact records:
| ID | First Name | Last Name | Company |
|---|---|---|---|
| 1 | Austin | Ehrhardt | Contoso |
| 2 | Austin | Ehrhardt |
We want to check if these two records are potential duplicates using a rule with the following setup:
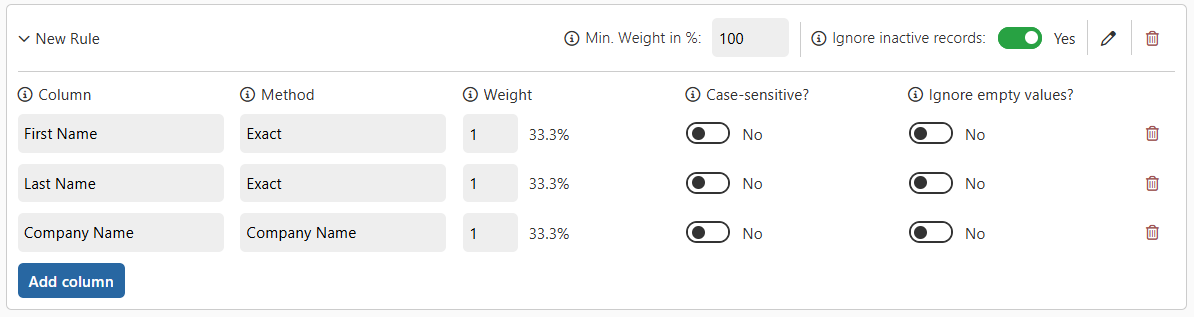
Scenario 1: “Ignore empty values” = No
This one is displayed in the rule screenshot. In this setup, if a column is empty, its weight does not count toward the total weight. In our example:
- First Name → matches → +33.3%
- Last Name → matches → +33.3%
- Company Name → does not match (empty on record 2) → +0%
Total: 66.6%, which is below the 100% minimum → no duplicate detected.
Scenario 2: “Ignore empty values” = Yes (for Company Name)
Now, the column Company Name contributes its weight even when empty. In our example:
- First Name → matches → +33.3%
- Last Name → matches → +33.3%
- Company Name → does not match (empty on record 2), but counts weight → +33.3%
Total: 100%, which meets the minimum → records flagged as potential duplicates.
Rule and Column Weight
Weight determines the importance of each column when comparing records; the higher the weight, the more impact that field has on reaching the match threshold. Adjusting weights allows you to fine-tune which fields are critical and which are less significant for duplicate detection.
Let’s consider the following rule:
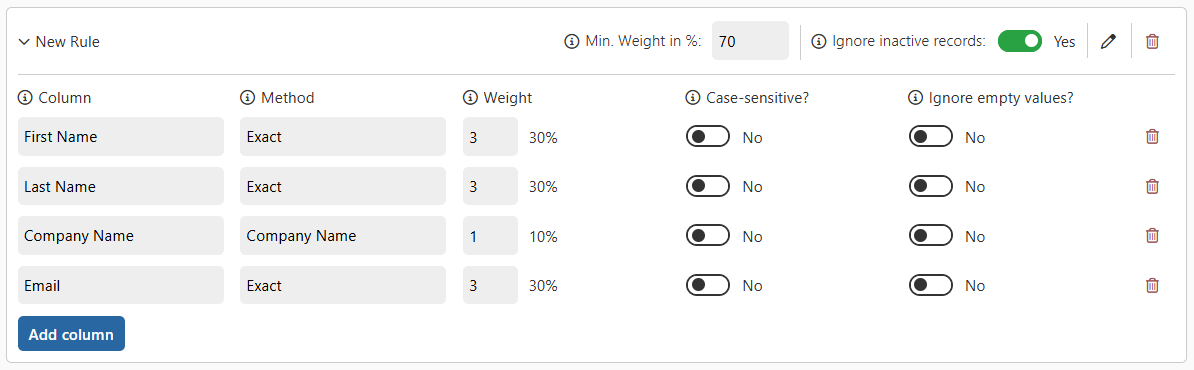
As we can see, to flag two records as potential duplicates, we need a total weight of at least 70%. Several combinations of columns can achieve this threshold:
- First Name + Last Name + Company Name
- First Name + Last Name + Email
- First Name + Email + Company Name
- Last Name + Email + Company Name
- First Name + Last Name + Company Name + Email
Let’s examine two contact records:
| ID | First Name | Last Name | Company Name | |
|---|---|---|---|---|
| 1 | Austin | Ehrhardt | Contoso | a.ehrhardt@contoso.com |
| 2 | Austin | Ehrhardt | Fabrikam | a.ehrhardt@contoso.com |
The weights for the columns are calculated as follows:
- First Name → matches → +30%
- Last Name → matches → +30%
- Company Name → does not match → +0%
- Email → matches → +30%
Total: 90%, which meets the minimum 70% → records flagged as potential duplicates.
Cross-Entity-Rule
Let’s consider the following rule:
As we can see, with this rule, the Company Name field of records in the Contact (1) entity is compared to the Account Name field of records in the Account (2) entity.
Let’s walk through a concrete example with one record from each entity:
| ID | First Name | Last Name | Company Name |
|---|---|---|---|
| 1 | Austin | Ehrhardt | Contoso |
| ID | Account Name | Adress 1: City | Primary Contact |
|---|---|---|---|
| 1 | Contoso | Paris | Austin Erhardt |
When applying our rule, we start with the source entity (Contact).
We look at the value in the configured field Company Name → “Contoso”.
Next, we check the target entity (Account) in the configured field Account Name → “Contoso”.
Since these two values match, the column’s weight is added to the total weight. In this example, the column carries 100% of the weight, so we reach the minimum required threshold.
As a result, the Account record with ID 1 (Contoso) is flagged as a potential duplicate of the Contact record with ID 1 (Austin Ehrhardt).
Didn't find what you were looking for?
Our team is ready to support you - reach out anytime and we’ll make sure you get the help you need.